這個問題的答案比我預期的複雜。我原本以為實驗結果會很直白:dynamic workflow 因為有重試機制,準確率就是比 static 高。結果確實如此——但原因完全不同。
這篇文章用同一份信用卡帳單資料,分別跑了靜態版(直接 Ollama 呼叫)和動態版(LangGraph StateGraph),記錄兩者的真實差距,以及讓我改變想法的那個發現。
The answer turned out to be more complicated than I expected. I assumed the experiment would be straightforward: dynamic workflow has retry logic, so accuracy would be higher. It was — but not for the reason I thought.
This article runs the same credit card billing dataset through both a static version (direct Ollama calls) and a dynamic version (LangGraph StateGraph), and reports the real-world difference between them, including the finding that changed my conclusion.
什麼是 Dynamic Workflow?
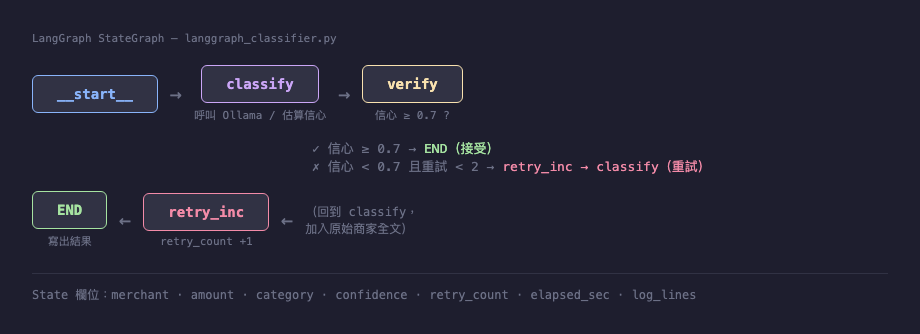
Static DAG(靜態有向無環圖):你把每一步寫死,機器照順序跑。n8n、Make、Zapier 都是這種模型。邏輯清楚,出錯容易追。
Dynamic Workflow:流程圖裡有「條件邊」可以回頭。AI 根據當前狀態決定下一步——接受結果、重試、或呼叫另一個工具。LangGraph 是目前最成熟的開源實作,它把工作流程包裝成 StateGraph:每個節點讀取狀態、輸出狀態,邊的走向由函式決定。
這兩種不是優劣之分,是不同適用場景。2025 年底這個詞突然變熱,因為三件事同時發生:Anthropic Claude Agent SDK 正式釋出、LangGraph 1.0 GA、n8n 加入 AI Agent node。
What is a Dynamic Workflow?
Static DAG (Directed Acyclic Graph): every step is hardcoded, executed in sequence. n8n, Make, Zapier — all this model. Logic is explicit, errors are traceable.
Dynamic Workflow: the graph has conditional edges that loop back. The AI decides the next step based on current state — accept the result, retry, or call a different tool. LangGraph wraps this into a StateGraph: each node reads state and outputs state, and edge routing is determined by a function.
These aren't better or worse. They solve different problems. The term went mainstream in late 2025 because three things happened simultaneously: Anthropic Claude Agent SDK went GA, LangGraph 1.0 released, and n8n shipped an AI Agent node.
實驗設計:同一份資料,兩種架構
輸入:12 個月匯豐信用卡帳單(與上一篇 n8n 文章同一份資料),取 40 筆代表樣本,跨月份、跨類別。
任務:把每筆交易歸類到 8 個消費類別(餐飲、訂閱服務、超市便利、交通、購物、水電通訊、醫療健康、娛樂休閒)。
版本 A — Static:Python 直接迴圈,每筆呼叫一次 Ollama,不管信心高低都接受第一次答案。
版本 B — Dynamic:LangGraph StateGraph,classify → verify → retry_inc → classify(信心 < 0.7 且重試次數 < 2 才回頭)。
兩個版本都用 gemma4:e2b(本地 Ollama,M1 MacBook 16GB),資料不出本機。
⚠️ 踩雷:gemma4:e2b 是 thinking model。第一次設定num_predict: 20,結果 405 筆全部回傳空字串——thinking tokens 把 token 預算吃完了。正確設定是num_predict: 2000,每筆約 8-10 秒。
Experiment Design: Same Data, Two Architectures
Input: 12 months of HSBC credit card statements (same dataset as the n8n billing article), 40 representative transactions sampled across months and categories.
Task: Classify each transaction into one of 8 spending categories (dining, subscriptions, groceries, transport, shopping, utilities, healthcare, entertainment).
Version A — Static: Direct Python loop, one Ollama call per transaction, accepts the first answer regardless of confidence.
Version B — Dynamic: LangGraph StateGraph, classify → verify → retry_inc → classify (loops back only when confidence < 0.7 and retries < 2).
Both versions use gemma4:e2b via local Ollama on an M1 MacBook 16GB. Data never leaves the machine.
⚠️ Gotcha: gemma4:e2b is a thinking model. Settingnum_predict: 20caused 405 consecutive empty responses — the thinking tokens consumed the entire token budget. The correct setting isnum_predict: 2000, at roughly 8–10 seconds per transaction.
Static 版本:132 行,直接了當
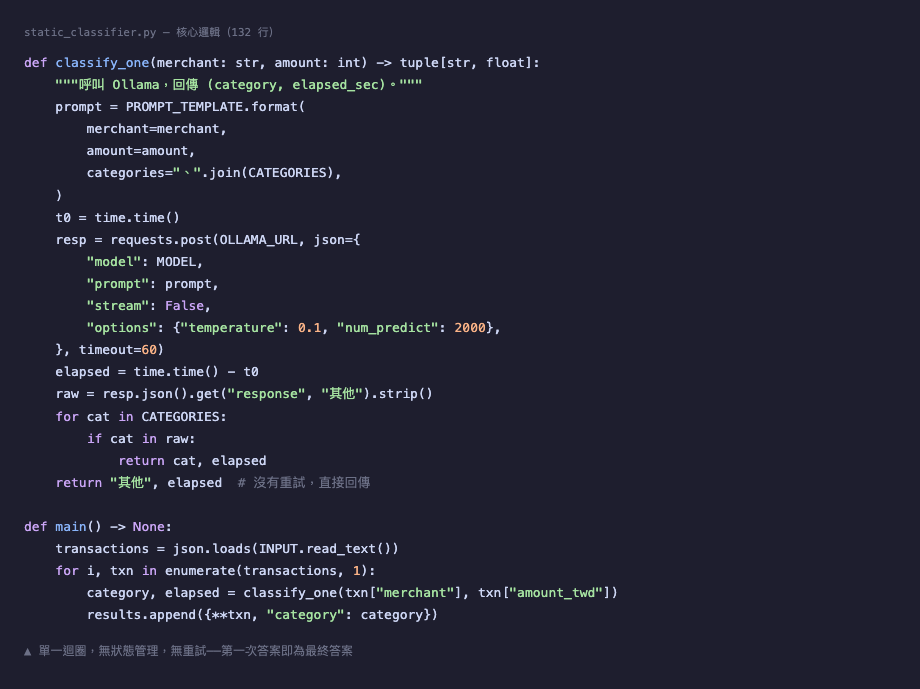

核心是一個迴圈:讀交易、組 prompt、打 Ollama、解析回答、存檔。沒有狀態管理,沒有重試邏輯。
Prompt 最後一行是:「如果不確定,回答『其他』。」
這句話在實驗中製造了麻煩。中油加油站出現 4 次,static 版給出了三種不同的分類:
| 筆次 | 商家 | Static 答案 |
|---|---|---|
| [009] | APE中油民生東路站 | 其他 ❌ |
| [014] | APE中油民生東路站 | 交通 ✅ |
| [020] | APE中油-金山南路站 | 超市便利 ❌ |
| [026] | APE中油-金山南路站 | 超市便利 ❌ |
同一個商家,四次,三種答案。這不是模型能力問題——是 prompt 的「不確定就回其他」這個後路,讓模型的決策在邊界案例上變得隨機。
Static Version: 132 Lines, Straightforward
The core is a single loop: read transaction, build prompt, call Ollama, parse response, save. No state management, no retry logic.
The last line of the prompt: "If unsure, answer '其他' (other)."
That sentence caused problems. The gas station chain 中油 appeared 4 times. Static gave three different answers:
| Transaction | Merchant | Static answer |
|---|---|---|
| [009] | APE中油 Minsheng Rd | 其他 (other) ❌ |
| [014] | APE中油 Minsheng Rd | 交通 (transport) ✅ |
| [020] | APE中油 Jinshan Rd | 超市便利 (grocery) ❌ |
| [026] | APE中油 Jinshan Rd | 超市便利 (grocery) ❌ |
Same merchant chain, four appearances, three different answers. This isn't a model capability problem — it's the "if unsure, answer other" escape hatch giving the model an inconsistent way out on borderline inputs.
Dynamic 版本:237 行,四個節點


StateGraph 定義了 4 個節點:
- classify:呼叫 Ollama,估算信心(精確命中類別名稱 = 0.9,否則 = 0.55)
- verify:信心 < 0.7 且重試次數 < 2 → 走重試路徑,否則接受
- retry_inc:重試計數 +1,回到 classify(第二次 prompt 加入商家原始全文)
- END:接受最終分類,寫出結果
Dynamic 版的 prompt 拿掉了「如果不確定,回答其他」這句,改成只給 8 個類別,要求直接命中其中一個。
實驗結果:重試機制在 40 筆裡一次都沒觸發。 每一筆的模型回答都精確命中類別名稱(信心 0.9),verify 節點直接放行。
但準確率還是從 77.3% 跳到 100%。
Dynamic Version: 237 Lines, Four Nodes
The StateGraph defines 4 nodes:
- classify: calls Ollama, estimates confidence (exact category match = 0.9, otherwise = 0.55)
- verify: confidence < 0.7 and retries < 2 → retry path; otherwise accept
- retry_inc: increments retry counter, returns to classify (second attempt includes original full merchant text)
- END: accepts final classification, writes result
The Dynamic prompt dropped the "if unsure, answer other" instruction and replaced it with a direct command to pick one of the 8 categories.
Experiment result: the retry mechanism never fired across all 40 transactions. Every model response hit a category name exactly (confidence 0.9), and the verify node waved it through.
But accuracy still jumped from 77.3% to 100%.
結果:改善來自哪裡?
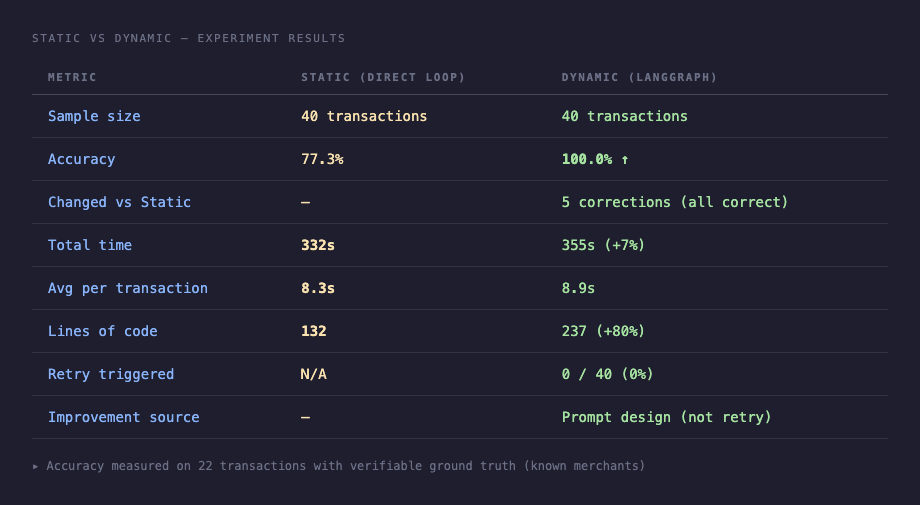
| 指標 | Static | Dynamic |
|---|---|---|
| 準確率(22 筆可驗證) | 77.3% | 100.0% ↑ |
| 修正筆數 | — | 5 筆(全部正確) |
| 總耗時 | 332s | 355s(+7%) |
| 平均 s/筆 | 8.3s | 8.9s |
| 程式碼行數 | 132 行 | 237 行(+80%) |
| 重試觸發 | 無 | 0 次 / 40 筆 |
| 改善來源 | — | Prompt 設計差異 |
5 筆修正全部來自同一個原因:dynamic prompt 沒有「不確定回其他」這條退路,模型必須在 8 個類別裡做出決定。中油三次全部正確地分到「交通」,KKBOX 和 Netflix 手續費也都歸到「訂閱服務」。
關鍵洞察:LangGraph 的節點設計逼你把每個 node 的指令想清楚。這個「設計副作用」可能比重試機制本身更有價值——即使重試從來沒有觸發。
Results: Where Did the Improvement Come From?
| Metric | Static | Dynamic |
|---|---|---|
| Accuracy (22 verifiable) | 77.3% | 100.0% ↑ |
| Corrections | — | 5 (all correct) |
| Total time | 332s | 355s (+7%) |
| Avg s/transaction | 8.3s | 8.9s |
| Lines of code | 132 | 237 (+80%) |
| Retry triggered | none | 0 / 40 (0%) |
| Improvement source | — | Prompt design difference |
All 5 corrections trace to the same cause: the Dynamic prompt removed the "if unsure, answer other" escape hatch, forcing the model to commit to one of the 8 categories. All three 中油 appearances correctly landed on "transport." KKBOX and the Netflix foreign transaction fee both went to "subscriptions."
Key insight: LangGraph's node-based design forces you to think carefully about each node's instructions. This design side effect may be more valuable than the retry mechanism itself — even when retries never fire.
決策框架:什麼情況選哪個
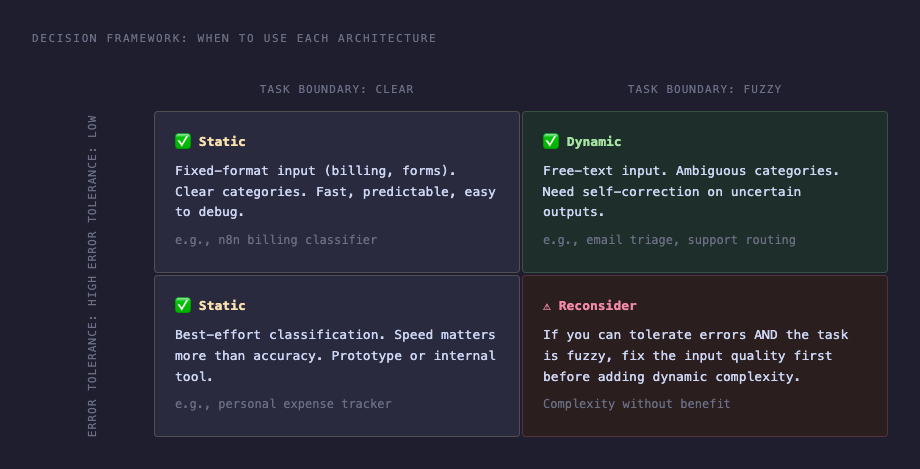
先問這個問題:你的問題是「模型給出了錯誤答案」,還是「模型給出了不確定的答案」?
- 「錯誤答案」(中油被分成超市便利)→ 先改 prompt,不需要 LangGraph
- 「不確定答案」(模型說「可能是 A 或 B」)→ retry 機制有用,考慮 Dynamic
選 Static 當:
- 輸入格式固定(帳單、表單、結構化資料)
- 分類邊界清楚,prompt 設計得當就能解決
- 重視可維護性,出錯要容易追
選 Dynamic 當:
- 輸入是自由文字,模型回答可能不規則(不是精確命中 label)
- 需要多步驟工具呼叫(搜尋商家資訊 → 再分類)
- 任務邊界模糊,需要明確的「自我修正」邏輯
- 預計未來要加更多節點(多模型路由、外部 API)
不要用 Dynamic 當:
- 只是想讓流程「感覺更 AI」
- 問題其實是 prompt 寫得不夠好(先修 prompt)
- 還沒有靜態版本作為基準
Dynamic workflow 的架構成本是真實的:237 行 vs 132 行,程式複雜度 +80%,每筆多 0.6 秒。如果改一句 prompt 能解決問題,就先改 prompt。
Decision Framework: Which One to Choose
Start with this question: is your problem "the model gave the wrong answer," or "the model gave an uncertain answer"?
- "Wrong answer" (中油 classified as grocery store) → fix the prompt first, no LangGraph needed
- "Uncertain answer" (model responds with "maybe A or B") → retry is useful, consider Dynamic
Choose Static when:
- Input format is fixed (statements, forms, structured data)
- Classification boundaries are clear — good prompt design solves it
- Maintainability matters, errors need to be traceable
Choose Dynamic when:
- Input is free text, model responses may be irregular (not exact label matches)
- Multi-step tool calls are needed (look up merchant info → re-classify)
- Task boundary is genuinely fuzzy and self-correction logic is required
- You expect to add more nodes later (multi-model routing, external APIs)
Don't use Dynamic when:
- You just want the flow to "feel more AI"
- The real problem is a poorly written prompt (fix the prompt first)
- You don't have a working static version as a baseline yet
The architectural cost of Dynamic is real: 237 lines vs 132, +80% code complexity, +0.6s per transaction. If one prompt change solves the problem, change the prompt.