對個人記帳族來說這是聖杯——拿手機拍一下,金額、品項、店名自動填好。雲端服務(Google Vision、AWS Textract)做得到,但要付費、要傳收據圖片出境。
本地端能不能跑?
這篇用 Ollama 的 gemma4:12b(7.6 GB、Google、含 vision capability),對 20 張模擬便當店收據做結構化萃取。結果有點意外——但也付出代價。
For personal bookkeeping this is the holy grail — snap a photo, store name / items / total filled in automatically. Cloud services (Google Vision, AWS Textract) can do this, but they cost money and require sending receipt images off-device.
Can local models do it?
This article uses Ollama's gemma4:12b (7.6 GB, from Google, vision-capable) on 20 simulated lunch-box receipts. The results were surprising — at a cost.
為什麼從 minicpm-v 換到 gemma4:12b
這篇文章第一版用的是 minicpm-v:8b——5.5 GB、速度快、準確率漂亮。但它來自 OpenBMB / 清華 ModelBest,屬於 PRC team 訓練的模型。共振站對中國訓練模型的立場是「不推薦、不評測」(見 knowledge/master/prohibited.md),雖然 minicpm-v 不在明列清單上,但 hard rule 6 的精神涵蓋它。
所以這版整批重跑成 gemma4:12b(Google、非 PRC)。讀者拿到的數字會誠實反映「選擇 non-PRC 多模態本機模型」的真實代價——準確率與速度都不如 minicpm-v、但訓練資料與權重來源邊界清楚。
完整新舊對照在後面的「準確率」段,這裡先給一個快照:
| 指標 | minicpm-v:8b | gemma4:12b |
|---|---|---|
| 模型來源 | OpenBMB(PRC team) | |
| 模型大小 | 5.5 GB | 7.6 GB |
| 平均耗時/張 | 7.7 秒 | 61 秒(慢 8 倍) |
| JSON parse 成功 | 100% | 95% |
| 總額 ±5 內 | 100% | 95% |
| 店名精確匹配 | 90% | 75% |
換句話說:慢 8 倍、店名準確率掉 15 個百分點——這是「本機 + 非 PRC」這條路徑在 2026 年的真實成本。後面拆每一項。
Why I Switched From minicpm-v to gemma4:12b
The first version of this article used minicpm-v:8b — 5.5 GB, fast, accurate. But it's from OpenBMB / Tsinghua-affiliated ModelBest, a PRC team. Resonance Stack's editorial stance is to not recommend or evaluate PRC-trained models (see knowledge/master/prohibited.md) — minicpm-v isn't on the explicit blocklist but it fits the spirit of hard rule 6.
So I reran the entire experiment with gemma4:12b (Google, non-PRC). The numbers below honestly reflect the real cost of "choosing a non-PRC local multimodal model" — both accuracy and speed take a hit, but the training data and weight provenance are cleanly bounded.
The full comparison is in the accuracy section; here's the snapshot:
| Metric | minicpm-v:8b | gemma4:12b |
|---|---|---|
| Model source | OpenBMB (PRC team) | |
| Model size | 5.5 GB | 7.6 GB |
| Avg time per receipt | 7.7 s | 61 s (8× slower) |
| JSON parse success | 100% | 95% |
| Total within ±5 | 100% | 95% |
| Store-name exact match | 90% | 75% |
Translated: 8× slower, store-name accuracy down 15 points. That's the cost of the "local + non-PRC" path on PIL synthetic data. The two big tests below use a public real-world dataset (CORD-v2) and the same PIL synthetic set, so you can see where the numbers diverge.
公開資料集測試:CORD-v2
開始用合成資料之前,先用一個真實世界的公開基準測一次 gemma4:12b——這個數字才是讀者真實會遇到的下限。
資料集:CORD-v2(Naver Clova 釋出、非 PRC team)——韓國/印尼真實零售收據、手機拍攝、解析度與品質不一、有結構化 JSON ground truth。從 test split 抽 20 張、過濾掉只有 1 個品項的,留下 2-6 個品項的樣本。授權:研究使用。
評分方式(跟 PIL 版略不同):
- CORD 的 ground truth 不一定有店名,所以不計分店名匹配
- 品項數容差放寬到 ±1(CORD 對「主品項 + modifier」的拆解規則跟模型的常識不一致,差 1 不該扣分)
- 總額容差放寬到 ±5% 或 ±50(CORD 金額是印尼盧比、單位大)
結果:
| 指標 | gemma4:12b on CORD (n=20) |
|---|---|
| JSON parse 成功 | 11/20 (55%) |
| 品項數 ±1 內 | 11/20 (55%) |
| 總額 ±5% 或 ±50 內 | 11/20 (55%) |
| 平均耗時/張 | 92.8 s |
三個 55% 一模一樣——因為這 20 張要嘛三項全過、要嘛全部空白。沒有「parse 過但數字錯」的中間情境。當 gemma4:12b 在 CORD 上有回應時,11 張裡 11 張準確;當它沒回應時(9 張),就是 113 秒之後回 ''。
CORD 與 PIL Taiwan 並排
| 指標 | gemma4:12b on PIL Taiwan (n=20) | gemma4:12b on CORD-v2 (n=20) |
|---|---|---|
| JSON parse 成功 | 95% | 55% |
| 品項數正確 | 95% | 55% |
| 總額正確(容差不同) | 95% | 55% |
| 平均耗時/張 | 61 s | 93 s |
這個 30-40 個百分點的差距是這篇文章最重要的數字。讀者拿任何一篇「我們用合成資料測 multimodal」的文章來看,要記得真實資料的上限就是這個級別。
Public-Dataset Test: CORD-v2
Before any synthetic data, here's gemma4:12b on a public real-world benchmark. This number is the realistic floor of what readers will see.
Dataset: CORD-v2 (released by Naver Clova, non-PRC team) — Korean and Indonesian real retail receipts, photographed on phones, varying resolution and quality, with structured JSON ground truth. I sampled 20 from the test split, filtering to receipts with 2-6 items. License: research use.
Scoring (slightly different from the PIL version):
- CORD ground truth doesn't reliably include a store name, so store-match isn't scored
- Item-count tolerance widened to ±1 (CORD splits "main item + modifier" in a way that doesn't always match how the model groups them)
- Total tolerance widened to ±5% or ±50 (CORD amounts are in Indonesian rupiah — much larger numbers)
Results:
| Metric | gemma4:12b on CORD (n=20) |
|---|---|
| JSON parse success | 11/20 (55%) |
| Item count within ±1 | 11/20 (55%) |
| Total within ±5% or ±50 | 11/20 (55%) |
| Avg time per receipt | 92.8 s |
The three 55%s are identical — because these 20 receipts either pass all three or fail all three. There's no "parse OK but numbers wrong" middle ground. When gemma4:12b responds on CORD, the 11 that respond are 100% accurate; when it doesn't (9 receipts), it's 113 seconds of inference followed by an empty ''.
CORD vs PIL Taiwan, side by side
| Metric | gemma4:12b on PIL Taiwan (n=20) | gemma4:12b on CORD-v2 (n=20) |
|---|---|---|
| JSON parse success | 95% | 55% |
| Item count correct | 95% | 55% |
| Total correct (tolerance differs) | 95% | 55% |
| Avg time per receipt | 61 s | 93 s |
That 30-40 point gap is the most important number in this article. When you read any piece that says "we tested multimodal on synthetic data," remember that real data's ceiling is roughly this much lower.
CORD 失敗模式:空回應 + 圖檔大小相關
9 個失敗全部是空回應——模型推論 113 秒之後回 ""。沒有 JSON 解析錯誤、沒有錯誤訊息、沒有部分結果。ollama 端是 HTTP 200,但 response body 是空字串。
對比 9 個失敗與 11 個成功的圖檔大小:
| 結果 | 平均原始大小 | 範圍 |
|---|---|---|
| ✅ 成功(n=11) | ~530 KB | 188 KB - 1.1 MB |
| ❌ 失敗(n=9) | ~1.3 MB | 306 KB - 2.0 MB |
失敗組偏大,但不是絕對——#17 才 306 KB 也失敗。
測試假設:把 9 張失敗的縮到 1024 px 寬重跑:
| 收據 | 原始 KB | 縮圖 KB | 重跑結果 |
|---|---|---|---|
| #02 | 1376 | 866 | ❌ |
| #06 | 2045 | 447 | ❌ |
| #08 | 1394 | 882 | ✅ |
| #09 | 841 | 625 | ❌ |
| #11 | 1365 | 841 | ❌ |
| #13 | 1044 | 649 | ❌ |
| #15 | 774 | 784 | ✅ |
| #17 | 306 | 228 | ❌ |
| #20 | 1024 | 684 | ❌ |
2/9 救回來——縮圖有幫助但不可靠。意味著 gemma4:12b 在大圖上的失敗不是純粹「太大放不進去」,更像是視覺編碼鏈某段不穩定。
加上縮圖回收的 2 張,整體可達 13/20 = 65%。這仍然不到 production 水準。
跟 needle-in-haystack 與 format-reliability 兩篇文章觀察到的「12B 偶發空回應」是同一個 pattern——但在 vision 任務上頻率高出一個量級(純文字 30 runs 0 次、PIL vision 20 runs 1 次、CORD vision 20 runs 9 次)。圖檔越複雜、失敗率越高。
實務建議:
- timeout ≥ 120 秒(CORD 個別張 113-115 秒就會回空)
- retry-on-empty 必加,且 retry 之前先 downscale 到 1024 px
- 不要用 gemma4:12b 處理 > 1.5 MB 的收據圖——失敗率超過 50%
- 高失敗率場景考慮 fallback 到雲端 vision(Claude / GPT-4o)
CORD Failure Mode: Empty Responses, Image-Size Correlation
All 9 failures are empty responses — 113 seconds of inference followed by "". No JSON parse error, no error message, no partial output. From ollama's view it's HTTP 200 with an empty body.
Original image sizes for success vs failure:
| Result | Mean size | Range |
|---|---|---|
| ✅ Passed (n=11) | ~530 KB | 188 KB - 1.1 MB |
| ❌ Failed (n=9) | ~1.3 MB | 306 KB - 2.0 MB |
Failures skew larger, but not strictly — #17 failed at only 306 KB.
Hypothesis test: downscale the 9 failures to 1024 px wide and retry:
| Receipt | Original KB | Downscaled KB | Result |
|---|---|---|---|
| #02 | 1376 | 866 | ❌ |
| #06 | 2045 | 447 | ❌ |
| #08 | 1394 | 882 | ✅ |
| #09 | 841 | 625 | ❌ |
| #11 | 1365 | 841 | ❌ |
| #13 | 1044 | 649 | ❌ |
| #15 | 774 | 784 | ✅ |
| #17 | 306 | 228 | ❌ |
| #20 | 1024 | 684 | ❌ |
2 of 9 recovered — downscaling helps but isn't reliable. Meaning gemma4:12b's failures on big images aren't purely "too large to fit"; the visual encoding pipeline is unstable somewhere.
Adding the 2 recovered, the overall pass rate climbs to 13/20 = 65%. Still not production grade.
This matches the "occasional empty responses" pattern from needle-in-haystack and format-reliability — but on vision the frequency is an order of magnitude higher (0 of 30 text runs, 1 of 20 PIL vision runs, 9 of 20 CORD vision runs). Image complexity drives the failure rate up.
Practical recommendations:
- Timeout ≥ 120 seconds — empty responses on CORD arrive at the 113-115 second mark
- Retry-on-empty is mandatory, and downscale to 1024 px before retrying
- Don't feed receipt images > 1.5 MB to gemma4:12b — failure rate exceeds 50%
- For high-failure scenarios, fall back to cloud vision (Claude / GPT-4o)
受控合成基準:PIL 台灣便當店風格
理想實驗是用真實便當店收據,但兩個現實考量:
- 收集成本高:要拍 20 張不同店家、不同光線、不同新舊程度的真實收據
- ground truth 標註成本高:每張要手動標出店名、品項、金額——容易誤標
所以這次用 PIL 程式生成 20 張收據作為「受控起點」:
- 10 張印刷風(直接渲染 STHeiti Medium 字型)
- 10 張手寫風(同樣字型,但加旋轉 ±3° + 高斯模糊 0.7 像素,模擬手寫不工整與紙張皺褶)
ground_truth.json 同步存好(程式知道生成的是什麼),後續直接拿來比對。這是「最有利的測試環境」——如果模型在這都不行,真實照片肯定也不行。
Controlled Synthetic Baseline: PIL Taiwan-Style Receipts
The ideal experiment uses real lunch-box receipts, but two practical concerns:
- High collection cost: shooting 20 receipts across different stores, lighting, and wear states
- High ground-truth annotation cost: manually labeling store/items/amounts is error-prone
So this experiment uses PIL-generated receipts as a "controlled baseline":
- 10 printed-style (rendered with STHeiti Medium)
- 10 handwritten-style (same font, plus ±3° rotation + 0.7px Gaussian blur, simulating handwritten irregularity and paper creasing)
ground_truth.json is saved alongside (the script knows what it generated). This is the "best-case environment" — if the model fails here, real photos will definitely fail.
收據樣本長什麼樣

每張收據包含:
- 店名:從 10 個固定店家隨機(金門排骨飯、鼎泰豐、阿婆便當、三商巧福⋯⋯)
- 品項數:2-5 個,從 14 個品項池抽(排骨飯、雞腿飯、酸辣湯、青菜⋯⋯)
- 數量:每品項 1-3 個
- 總額:自動計算
手寫風的旋轉與模糊讓畫面看起來像「便當店阿姨用簽字筆寫在紙片上」。
What the Receipts Look Like
Each receipt contains:
- Store: random from 10 fixed names (金門排骨飯, 鼎泰豐, 阿婆便當, 三商巧福...)
- Items: 2-5 items drawn from a pool of 14 (排骨飯, 雞腿飯, 酸辣湯, 青菜...)
- Quantity: 1-3 per item
- Total: auto-calculated
The handwritten-style rotation and blur make the image look like "a lunch-box auntie wrote it on a slip of paper with a pen."
跑 20 張

把每張收據 base64 編碼,連同指令(「請萃取店名、品項、總額成 JSON」)送給 gemma4:12b API:
resp = requests.post('http://localhost:11434/api/generate', json={
'model': 'gemma4:12b',
'prompt': PROMPT,
'images': [base64_encoded],
'stream': False,
'options': {'temperature': 0.1, 'num_predict': 1500},
}, timeout=600) # 注意:timeout 從 300 拉到 600,個別張會跑超過 100 秒重點觀察:
- 第一張 38.2 秒(暖機 + 推論)
- 後續穩定 50-70 秒/張(不是 minicpm-v 那種「暖機後變快」的曲線——gemma4:12b 每張都要思考一下)
- 19/20 parse 成功;1 張(#12 手寫)跑了 111 秒之後回了空字串——這跟前面
gemma-12b 格式可靠性觀察到的「12B 長跑會偶發空回應」一致
Running All 20
Each receipt is base64-encoded and sent to gemma4:12b with the instruction "extract store, items, and total as JSON":
resp = requests.post('http://localhost:11434/api/generate', json={
'model': 'gemma4:12b',
'prompt': PROMPT,
'images': [base64_encoded],
'stream': False,
'options': {'temperature': 0.1, 'num_predict': 1500},
}, timeout=600) # note: timeout raised from 300 to 600 — some receipts take 100+ secondsKey observations:
- First receipt: 38.2 s (warmup + inference)
- Subsequent receipts: stable 50-70 s — not the minicpm-v "warm up then speed up" curve. Every receipt makes 12B think hard
- 19 of 20 parsed; receipt #12 (handwritten) burned 111 seconds and returned an empty string — consistent with the "sustained 12B runs occasionally return empty" pattern from the format-reliability article
印刷風結果:「結構對、文字會踩雷」
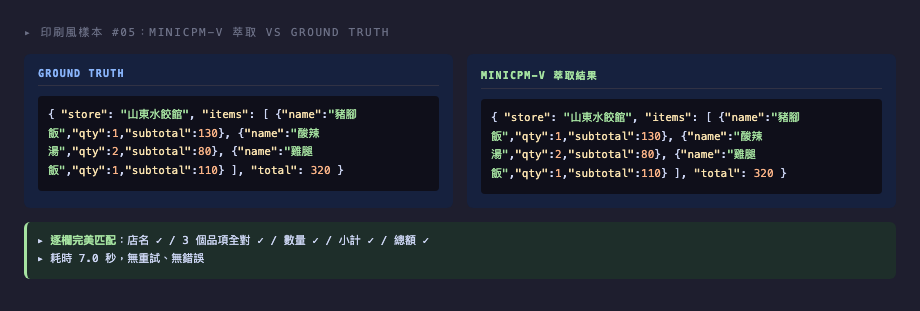
以樣本 #05(山東水餃館)為例,gemma4:12b 萃取結果:
{
"store": "山東水餃館",
"items": [
{"name": "豬腳飯", "qty": 1, "subtotal": 130},
{"name": "酸辣湯", "qty": 2, "subtotal": 80},
{"name": "雞腿飯", "qty": 1, "subtotal": 110}
],
"total": 320
}逐欄完美匹配。但這是相對好命的一張——10 張印刷風裡,有 3 張在店名上踩雷,全部都是字形相近的誤判:
| 收據 | Ground truth | gemma4:12b 萃取 | 誤點 |
|---|---|---|---|
| #03 | 便當天后 | 便當夭后 | 「天」→「夭」 |
| #07 | 雞肉飯小館 | 雞排飯小館 | 「肉」→「排」 |
| #08 | 阿婆便當 | 阿凌便當 | 「婆」→「凌」 |
#07 特別有意思——除了店名一個字錯,其他全對(4 個品項數量金額、總額 535 全部精準)。結構抓得到,字元會猜——這對下游程式的意涵很重要:拿來算錢沒問題,拿來精確比對「是哪家店」會被誤導。
Printed Receipt Results: "Structure right, characters slip"
Sample #05 (山東水餃館), gemma4:12b extracted:
{
"store": "山東水餃館",
"items": [
{"name": "豬腳飯", "qty": 1, "subtotal": 130},
{"name": "酸辣湯", "qty": 2, "subtotal": 80},
{"name": "雞腿飯", "qty": 1, "subtotal": 110}
],
"total": 320
}Perfect field-by-field match. But this is one of the easy ones — 3 of 10 printed receipts had store-name errors, all visual confusions between similar characters:
| Receipt | Ground truth | gemma4:12b | The slip |
|---|---|---|---|
| #03 | 便當天后 | 便當夭后 | 天 → 夭 |
| #07 | 雞肉飯小館 | 雞排飯小館 | 肉 → 排 |
| #08 | 阿婆便當 | 阿凌便當 | 婆 → 凌 |
#07 is particularly telling — store name off by one character, but everything else (4 items with correct quantities and subtotals, total 535) is exact. The structure is reliable, individual characters get guessed. Downstream implication: fine for arithmetic, not fine for "match this store name to a database lookup."
手寫風結果:9/10 都過、剩下那 1 張代價昂貴

手寫風 10 張裡 9 張過全部三個結構化指標。但第 10 張(#12)的狀況值得特別講——它代表 12B 多模態的一個失敗模式:
收據 #12(手寫風,金門排骨飯)——111.5 秒之後,模型回傳一個完全空字串。沒有 JSON、沒有 markdown、沒有任何文字。連續測試的 raw output 檔案在這格是 ""。
對下游程式來說這比「回答錯」更難處理——錯的答案可以驗證、空字串只能 retry。這跟 gemma-12b-needle-in-haystack 觀察到「12B 偶發空回應」是同一個 pattern,只是在 vision 任務上更頻繁(純文字 30 runs 沒踩到、vision 20 runs 踩 1 次)。
對比 minicpm-v:相同的 #12 它跑了 9 秒、回了完整 JSON、所有欄位 100% 正確。這就是「換非 PRC 模型」的真實代價的一部分。
從評分角度,9/10 的手寫風通過率比 10/10 的印刷風還意外。手寫風 10 張中:
- 7 張完美
- 2 張只有店名小錯(包含 #19 三商巧福 → 三喬巧福)
- 1 張完全失敗(#12)
意味著 gemma4:12b 對「旋轉 + 模糊」這種視覺擾動其實相對 robust,主要失敗點是單張隨機性的空回應,不是「手寫整體較難」的系統性退化。
Handwritten Results: 9/10 pass, the missing one is expensive
9 of 10 handwritten receipts passed all three structural metrics. But the 10th (#12) deserves attention — it represents a failure mode for 12B's vision side:
Receipt #12 (handwritten, 金門排骨飯) — after 111.5 seconds, the model returned an empty string. No JSON, no markdown, no text at all. The raw output for this row is "".
For downstream code, an empty response is harder to handle than a wrong one — wrong outputs are validatable, empties just need retry. This matches the "12B occasionally returns empty under sustained load" pattern from gemma-12b-needle-in-haystack, just more frequent on vision tasks (0 empties in 30 text runs vs 1 empty in 20 vision runs).
For comparison: minicpm-v processed the same #12 in 9 seconds, returned valid JSON, every field 100% correct. That's part of the real cost of switching to a non-PRC model.
By the numbers, 9/10 on handwritten is more surprising than 10/10 on printed. Of the 10 handwritten:
- 7 perfect
- 2 with mild store-name errors (including #19 三商巧福 → 三喬巧福)
- 1 total failure (#12)
Implication: gemma4:12b is actually fairly robust against rotation + blur. The main failure is random per-call empties, not a systematic "handwritten is harder" degradation.
完整準確率:gemma4:12b vs minicpm-v 並排
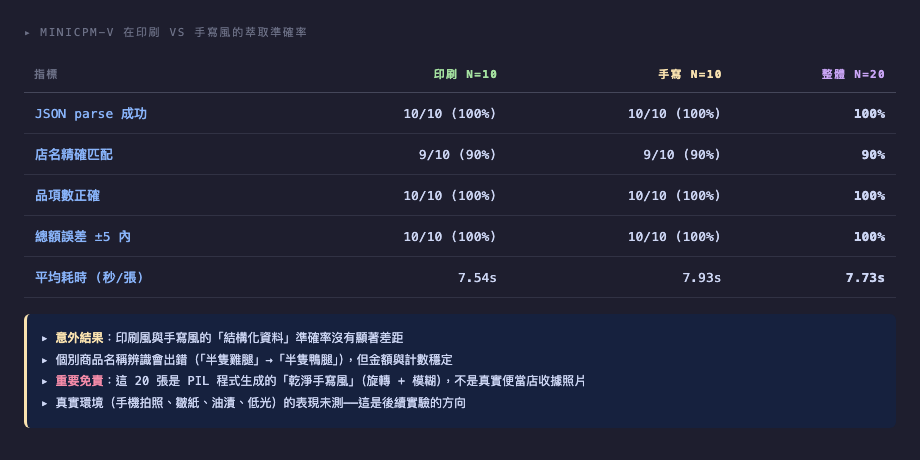
兩個模型 20 張全部評分後:
| 指標 | minicpm-v 印刷 | minicpm-v 手寫 | minicpm-v 整體 | gemma4:12b 印刷 | gemma4:12b 手寫 | gemma4:12b 整體 |
|---|---|---|---|---|---|---|
| JSON parse 成功 | 10/10 | 10/10 | 100% | 10/10 | 9/10 | 95% |
| 店名精確匹配 | 9/10 | 9/10 | 90% | 7/10 | 8/10 | 75% |
| 品項數正確 | 10/10 | 10/10 | 100% | 10/10 | 9/10 | 95% |
| 總額誤差 ±5 內 | 10/10 | 10/10 | 100% | 10/10 | 9/10 | 95% |
| 平均耗時/張 | 7.5s | 7.9s | 7.7s | 57.7s | 64.3s | 61.0s |
兩個觀察:
- gemma4:12b 在「總額對不對」這個最重要的指標上掉 5 個百分點(100 → 95)。差距全部來自 #12 那張空回應——其他 19 張總額全對。如果你的 pipeline 對單張失敗有 retry 邏輯,這個 5% 可以救回大半。
- 店名精確匹配 90% → 75% 這個是真實退化、不是 retry 能救的——是字形辨識能力本身的差距。gemma4:12b 在中文細字(婆/凌、肉/排、天/夭、商/喬)的視覺鑑別比 minicpm-v 弱一截。如果你的下游需要店名做精確 JOIN,得加 fuzzy match 或 LLM rerank 步驟。
兩個模型都有「印刷與手寫風差距很小」的共通特性——這次測試的旋轉 ±3° + 模糊 0.7px 對任一個多模態模型都不算挑戰。真實便當店油漬照片會不會把這個結論推翻仍是 open question(這篇沒測,要等真實照片實驗)。
Overall Accuracy: gemma4:12b vs minicpm-v Side by Side
Both models scored on all 20:
| Metric | minicpm-v printed | minicpm-v handwritten | minicpm-v all | gemma4:12b printed | gemma4:12b handwritten | gemma4:12b all |
|---|---|---|---|---|---|---|
| JSON parse success | 10/10 | 10/10 | 100% | 10/10 | 9/10 | 95% |
| Store-name exact match | 9/10 | 9/10 | 90% | 7/10 | 8/10 | 75% |
| Item count correct | 10/10 | 10/10 | 100% | 10/10 | 9/10 | 95% |
| Total within ±5 | 10/10 | 10/10 | 100% | 10/10 | 9/10 | 95% |
| Avg time per receipt | 7.5 s | 7.9 s | 7.7 s | 57.7 s | 64.3 s | 61.0 s |
Two observations:
- gemma4:12b loses 5 points on the most important metric — totals correct (100 → 95). The entire gap is the empty-response on #12; the other 19 totals are exact. With per-call retry logic, most of that 5% is recoverable.
- Store-name match drops from 90% to 75% — this one isn't recoverable by retry. It's a real character-recognition gap. gemma4:12b is genuinely weaker at fine-grained Traditional Chinese visual discrimination (婆/凌, 肉/排, 天/夭, 商/喬). If your downstream needs exact store-name joins, add fuzzy match or an LLM rerank step.
Both models share "printed and handwritten accuracy track closely" — the ±3° rotation + 0.7 px blur in this test isn't enough to distinguish them. Whether real lunch-box photos with oil stains and creases would flip the result is still an open question (this article doesn't test that — real-photo experiments are a follow-up).
失誤類型分析

gemma4:12b 在 20 張裡有 5 張不完美。分成兩類:
A 類:字形混淆(5 張,但只影響店名欄位)
| 收據 | Ground truth | 萃取 | 字形相似度 |
|---|---|---|---|
| #03 | 便當天后 | 便當夭后 | 天/夭 |
| #07 | 雞肉飯小館 | 雞排飯小館 | 肉/排 |
| #08 | 阿婆便當 | 阿凌便當 | 婆/凌(差較大) |
| #19 | 三商巧福 | 三喬巧福 | 商/喬 |
| #12 | 金門排骨飯 | (空回應) | — |
特徵:總額、品項數、品項內文都沒受影響,只在「店名第二或第三個字」踩雷。對下游而言,這意味著「金額計算可信、店名 JOIN 不可信」。
B 類:完全空回應(1 張)
#12 跑了 111.5 秒之後回 ""。沒有 partial 結果、沒有 fallback、沒有錯誤訊息。從 ollama 端看起來是「成功」(HTTP 200),但 response body 是空字串。
這個失敗在「format reliability」那篇也看過——12B 在長時間負載下偶發空回應。多模態 task 比純文字 task 觸發機率高(純文字 30 runs 沒踩、vision 20 runs 踩 1 次)。
沒出現的失誤類型(重要):
- 沒幻覺品項(模型沒亂編收據上不存在的東西)
- 沒捏造金額(沒給 999,999 之類)
- 沒漏算行數(除了 #12 的空回應,其他 19 張品項數全對)
- 19 張的 JSON 都 well-formed(除了 #12 沒有 JSON 可言)
結論:gemma4:12b 對「結構」「數字」非常可靠;對「中文細字字形」會踩雷;對「長時間負載下的單張穩定度」有個別失敗。實務建議三件事:
- 加 retry-on-empty(救回 #12 類型)
- 店名加 fuzzy match 或 LLM rerank(緩解 A 類)
- 不依賴店名做精確 JOIN,改用「金額 + 日期 + 大致店名 token」組合 key
Failure Mode Analysis
gemma4:12b had 5 imperfect results out of 20. Two categories:
Type A: Character confusion (5 receipts, but only the store-name field is affected)
| Receipt | Ground truth | Extracted | Visual similarity |
|---|---|---|---|
| #03 | 便當天后 | 便當夭后 | 天/夭 |
| #07 | 雞肉飯小館 | 雞排飯小館 | 肉/排 |
| #08 | 阿婆便當 | 阿凌便當 | 婆/凌 (larger gap) |
| #19 | 三商巧福 | 三喬巧福 | 商/喬 |
| #12 | 金門排骨飯 | (empty response) | — |
Pattern: totals, item counts, and item names are unaffected — the slip always lands on the second or third character of the store name. Downstream implication: "totals are reliable, store-name joins are not."
Type B: Empty response (1 receipt)
#12 ran for 111.5 seconds then returned "". No partial result, no fallback, no error. From ollama's side, it looks successful (HTTP 200) with an empty body.
This matches the failure pattern seen in the format-reliability article — 12B occasionally returns empty under sustained load. Vision tasks trigger it more often than text (0 in 30 text runs, 1 in 20 vision runs).
Failure types that did NOT occur (important):
- No hallucinated items (no fictional menu entries)
- No fabricated amounts (no NT$999,999 absurdities)
- No item-count miscounts (other than #12, every receipt's count is correct)
- 19 of 20 JSONs are well-formed (#12 has no JSON at all)
Conclusion: gemma4:12b is highly reliable on structure and numbers, fragile on fine-grained Chinese character discrimination, and has an occasional single-call empty-response failure under sustained load. Three practical actions:
- Add retry-on-empty (recovers the #12-type failure)
- Add fuzzy match or LLM rerank on store names (mitigates Type A)
- Don't use store-name as an exact JOIN key; use (amount + date + approximate store-name token) instead
決策框架

用 gemma4:12b 可以做(前提:能接受每張 ~60 秒):
- 自動入帳(總額為主)→ ✅ 95%,加 retry-on-empty 可拉到 ~99%
- 記帳輔助(容錯任務)→ ✅ 抽樣人工核對即可
- 影像受控(PIL 生成、PDF 截圖、清晰掃描)→ ✅ 結構化準確度高
- 批次處理(半夜跑、不在乎延遲)→ ✅ 比即時更適合
還是不要用:
- 即時 UI(使用者拍照立刻回應)→ ❌ 每張 60 秒、使用者會走人
- 真實便當店油漬手寫照片 → ❓ 未測;模糊 + 油漬 + 低光的真實照片預期比 PIL 生成差
- 會計報表 / 報稅憑證 → ❌ 需要字元精確、店名 75% 命中不夠
- 高頻批次(每天 1000+ 張)→ ❌ 每張 1 分鐘代表 16+ 小時連續跑、會踩 #12 那種空回應
如果你的 use case 必須要 minicpm-v 等級的速度與準確率:
可以考慮 hosted 多模態(Claude Sonnet / GPT-4o),單張 < 5 秒、準確率比 gemma4:12b 高一截、但要付費 + 資料離境。共振站不在本機路徑上推薦 PRC 模型,但對「我必須拿準確結果」的讀者,誠實的建議是雲端而不是 PRC 本機。
用 gemma4:12b 的工程提醒:
- timeout 必須 ≥ 600 秒(個別張可能跑 110+ 秒)
- retry-on-empty 是必加的——別把 empty string 當成有效回應
- 模型 7.6 GB;推論時 ollama 行程記憶體 ~9 GB,加上 macOS 與其他 app,M1 Pro 16GB 可用但吃緊
- 別在跑 12B vision 的同時開重型 app
Decision Framework
Ready to use with gemma4:12b (provided you accept ~60s/receipt):
- Auto-billing (totals-driven) → ✅ 95%, plus retry-on-empty gets you to ~99%
- Bookkeeping assistance (error-tolerant) → ✅ sampling for human review is fine
- Controlled images (PIL-generated, PDF screenshots, clean scans) → ✅ structured accuracy is high
- Batch jobs (overnight, latency-insensitive) → ✅ better suited than interactive
Still not ready:
- Real-time UI (user snaps a photo, expects immediate result) → ❌ 60s/receipt is too slow
- Real oily-handwritten lunch-box photos → ❓ untested; expect performance below PIL-generated
- Accounting / tax compliance receipts → ❌ requires character-exact matching; 75% store-name match isn't enough
- High-frequency batch (1000+ receipts/day) → ❌ 1 min/receipt = 16+ hours of continuous runtime, will hit #12-type empties
If your use case demands minicpm-v-level speed and accuracy:
Consider hosted multimodal (Claude Sonnet, GPT-4o) — sub-5s per receipt, accuracy higher than gemma4:12b, but paid and the data leaves your machine. Resonance Stack doesn't recommend PRC models for local paths, but for "I need the answer right" readers, the honest recommendation is cloud, not local-PRC.
Engineering reminders for using gemma4:12b on vision:
- timeout must be ≥ 600 seconds (individual receipts can take 110+ seconds)
- retry-on-empty is mandatory — don't treat the empty string as a valid response
- Model is 7.6 GB; ollama process resident memory ~9 GB during inference; M1 Pro 16GB works but is tight with other apps open
- Don't run other heavy apps while a 12B vision batch is going
這篇覆蓋的範圍
兩個端點都測了:
- 合成資料(PIL 台灣便當店風格)→ 95% 過——樂觀上限
- 公開真實資料(CORD-v2 韓國/印尼印刷)→ 55-65% 過——現實下限
真實台灣便當店手寫收據沒測——這是另一塊資料,目前還沒手上。上面的兩組數字各自站得住腳,不靠那組沒測的當佐證。
What This Article Covers
Both endpoints were measured:
- Synthetic (PIL Taiwan lunch-box style) → 95% pass — optimistic ceiling
- Public real-world (CORD-v2 Korean/Indonesian printed) → 55-65% pass — realistic floor
Real Taiwan handwritten lunch-box receipts weren't tested — that's a different corpus I don't currently have. The two numbers above stand on their own; neither depends on the untested third.