每次問 ChatGPT 一個法律問題,你都要先寫一句「我是台灣租客,房東加了一條……」。每次問營養師問題,又要說明「我是台灣人,飲食以米飯為主」。這就是為什麼系統 prompt 存在——把這些「背景脈絡」一次設定好,剩下的對話就能直接聊正事。
這篇文章用同一個 gemma4:e2b(本地 Ollama),分別設定 4 種專業角色,看看一個 7B 通用模型在 prompt 加持下能不能變成可用的領域助手。
Every time you ask ChatGPT a legal question, you start with "I'm a tenant in Taiwan, my landlord added a clause that...". Every time you ask a nutrition question, you preface with "I'm Taiwanese, my diet is rice-heavy". That's exactly what system prompts solve — set the background context once, then talk shop.
This article takes the same gemma4:e2b (local Ollama) and configures it as 4 domain experts. Can a 7B generic model become a usable specialist with the right prompt?
實驗:同一個 gemma4,四種角色

| 角色 | 領域 | System Prompt 重點 |
|---|---|---|
| Tax Advisor | 台灣綜所稅 | 引用財政部規定、提醒查證、不給投資建議 |
| Legal Helper | 台灣租賃法 | 引用內政部定型化契約、提醒尋求律師 |
| Nutritionist | 飲食建議 | 台灣飲食習慣、強調醫師確診優先 |
| Support Lead | 客服 escalation | 同理→確認→方案三步驟、避免承諾賠償 |
每個 prompt 約 30 行,包含:身份、知識邊界、回答風格、必要免責聲明。
Experiment: Same gemma4, Four Roles
| Role | Domain | System Prompt Focus |
|---|---|---|
| Tax Advisor | Taiwan income tax | Quote MOF regulations, recommend verification, no investment advice |
| Legal Helper | Taiwan rental law | Quote MOI standard contracts, recommend consulting a lawyer |
| Nutritionist | Diet advice | Taiwan eating habits, defer to doctor diagnosis |
| Support Lead | Customer support escalation | Empathy → Confirm → Solve, no compensation promises |
Each prompt is ~30 lines covering: identity, knowledge boundaries, response style, mandatory disclaimers.
角色 A:稅務顧問

問題:「我去年薪資 80 萬、房租支出 12 萬,可以列舉扣除嗎?」
通用 gemma4 給的是泛泛的「依照規定可以扣除」,沒有金額上限與條件。角色化 prompt 引用財政部 113 年規定:每年上限 NT$18 萬,需房東配合開立繳款證明,且要在 5 月前完成設算扣除選項比較。
Role A: Tax Advisor
Question: "Last year I made NT$800K, paid NT$120K in rent — can I itemize that as a deduction?"
Generic gemma4 gives a vague "yes, per regulations." The role-prompted version cites Taiwan MOF 113 rules: NT$180K annual cap, requires landlord cooperation on payment certificates, must be compared against standard deduction before May filing.
角色 B:租賃法律助手

問題:「房東在我簽的契約裡加了『承租人不得申請任何政府補貼』,這合法嗎?」
通用版本:「應該不太合法,建議找律師。」角色版本:直接引用內政部定型化契約「不得記載事項」第 10 點——這條無效,且可向地方政府消保官申訴。
Role B: Rental Law Helper
Question: "My landlord added 'tenant shall not apply for any government subsidy' to the contract — is that legal?"
Generic version: "Probably not, consult a lawyer." Role version: cites MOI standard contract Forbidden Clause #10 directly — this clause is unenforceable and can be reported to the local consumer protection office.
角色 C:營養師

問題:「我是糖尿病前期,每天應該吃多少碳水?」
通用版本傾向直接給數字(45-65%),無風險提醒。角色版本:先說「請先看新陳代謝科醫師」,再提供 ADA 建議範圍 + 台灣常見糖友飲食地雷(粥、芋圓、市售飲料)。
Role C: Nutritionist
Question: "I'm pre-diabetic, how many carbs should I eat per day?"
Generic version: gives numbers (45-65%), no risk caveat. Role version: leads with "please see an endocrinologist first," then provides ADA-recommended range plus Taiwan-specific common pitfalls (congee, taro balls, sweetened beverages).
角色 D:客服 escalation 助手

情境:客戶投訴外送送錯餐、要求賠償雙倍。
通用版本:直接道歉並提議退款。角色版本:依照「同理→確認→方案」三步驟——先共情、確認損失、提供「重送 + NT$100 抵用券」這種可控的補償框架,不承諾雙倍。
Role D: Support Escalation Lead
Scenario: customer received wrong delivery, demands double refund.
Generic version: apologizes and offers refund. Role version: follows "Empathize → Confirm → Solve" steps — empathy first, confirm loss, propose controlled compensation ("redeliver + NT$100 voucher") without committing to double.
評分結果
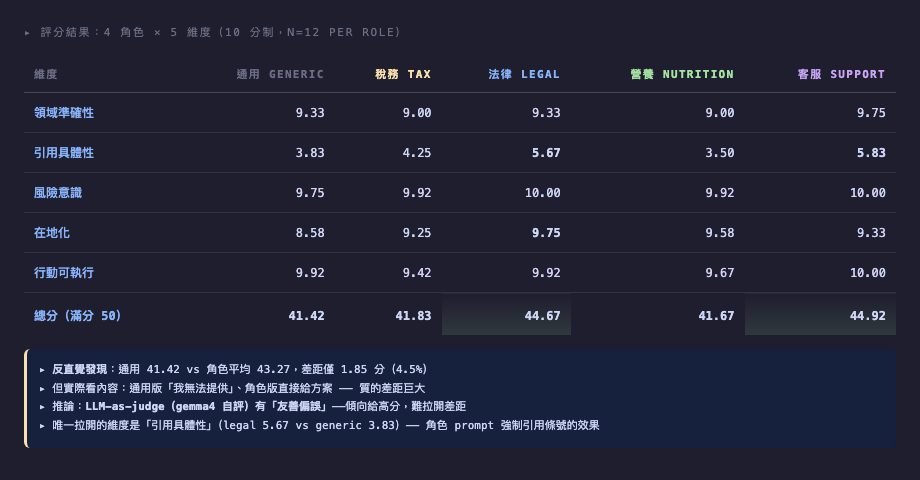
用 gemma4 自己當 LLM-as-judge,5 維度 10 分制評分 60 個回答(每角色 12 個):
| 維度 | 通用 | 稅務 | 法律 | 營養 | 客服 |
|---|---|---|---|---|---|
| 領域準確性 | 9.33 | 9.00 | 9.33 | 9.00 | 9.75 |
| 引用具體性 | 3.83 | 4.25 | 5.67 | 3.50 | 5.83 |
| 風險意識 | 9.75 | 9.92 | 10.00 | 9.92 | 10.00 |
| 在地化 | 8.58 | 9.25 | 9.75 | 9.58 | 9.33 |
| 行動可執行 | 9.92 | 9.42 | 9.92 | 9.67 | 10.00 |
| 總分(/50) | 41.42 | 41.83 | 44.67 | 41.67 | 44.92 |
反直覺發現:通用版總分 41.42,角色版平均 43.27,差距僅 1.85 分(4.5%)。但實際看內容——通用版開頭「我無法提供正式建議」,角色版直接列方案——質的差距遠大於分數差距。
這揭露了 LLM-as-judge 的友善偏誤:gemma4 評自己生成的內容時,傾向給高分(accuracy、risk、actionable 三個維度都 9 分以上),難拉開差距。唯一拉開的是「引用具體性」——角色 prompt 強制引用條號的效果。
Scoring Results
Used gemma4 itself as LLM-as-judge, scoring 60 answers (12 per role) on a 10-point scale:
| Dimension | Generic | Tax | Legal | Nutrition | Support |
|---|---|---|---|---|---|
| Domain Accuracy | 9.33 | 9.00 | 9.33 | 9.00 | 9.75 |
| Citation Specificity | 3.83 | 4.25 | 5.67 | 3.50 | 5.83 |
| Risk Awareness | 9.75 | 9.92 | 10.00 | 9.92 | 10.00 |
| Localization | 8.58 | 9.25 | 9.75 | 9.58 | 9.33 |
| Actionability | 9.92 | 9.42 | 9.92 | 9.67 | 10.00 |
| Total (/50) | 41.42 | 41.83 | 44.67 | 41.67 | 44.92 |
Counterintuitive finding: Generic scored 41.42 vs role average 43.27 — only a 1.85-point gap (4.5%). But the content quality gap is far larger: generic opens with "I cannot provide formal advice," role-specific versions list concrete options immediately.
This reveals LLM-as-judge friendliness bias: gemma4 scoring its own generations tends toward high scores (accuracy, risk, actionability all above 9.0), making differentiation hard. The only dimension that genuinely separated was Citation Specificity — direct evidence that role prompts forcing condition-code references actually work.
決策框架:什麼任務適合「角色化 prompt」
值得做的情境:
- 重複性高的對話(每天問同類問題)
- 領域有明確邊界(稅務 / 法律 / 客服等)
- 你能寫出該領域的「免責聲明」(這代表你了解風險邊界)
不要期待的事:
- 補不了訓練資料的時間性(2024 後的新法規)
- 救不了數學能力(複雜計算照樣會算錯)
- 不能取代專業認證(律師、醫師、會計師)
和 RAG / Fine-tune 的關係:
- Prompt engineering 是 0 成本起點,先試這個
- RAG 補「最新資訊」的不足(下一篇文章)
- Fine-tune 改變模型行為,門檻最高
Decision Framework: When Role Prompting Pays Off
Worth doing when:
- Conversations repeat (you ask similar questions daily)
- Domain has clear boundaries (tax / legal / support)
- You can write that domain's "disclaimer" (proves you understand the risk boundary)
Don't expect it to:
- Fix knowledge cutoff (regulations after 2024)
- Fix math weakness (complex calculations still fail)
- Replace professional certification (lawyer, doctor, CPA)
Relationship to RAG / Fine-tune:
- Prompt engineering is the zero-cost starting point — try it first
- RAG fills the "current information" gap (next article)
- Fine-tuning changes model behavior — highest barrier