我自己已經寫了 5 篇關於 Ollama、n8n、LangGraph 的文章。一個月後,當我想回憶「LangGraph 重試成功率到底是多少」,我會打開部落格、用瀏覽器 Cmd+F、滾上滾下找答案。
這個情境就是 RAG(Retrieval-Augmented Generation)解決的問題:把你寫過的所有東西變成 LLM 可以查的知識庫。
這篇文章用全本地工具實作:Ollama(gemma4 + nomic-embed-text)+ ChromaDB + 200 行 Python。
I've written 5 articles on Ollama, n8n, and LangGraph. A month later, when I want to remember "what was LangGraph's retry success rate again?" — I open the blog, hit Cmd+F, scroll up and down hunting for it.
That's exactly the problem RAG (Retrieval-Augmented Generation) solves: turn everything you've written into a searchable knowledge base for an LLM.
This article does it with fully local tooling: Ollama (gemma4 + nomic-embed-text) + ChromaDB + ~200 lines of Python.
RAG 三步驟
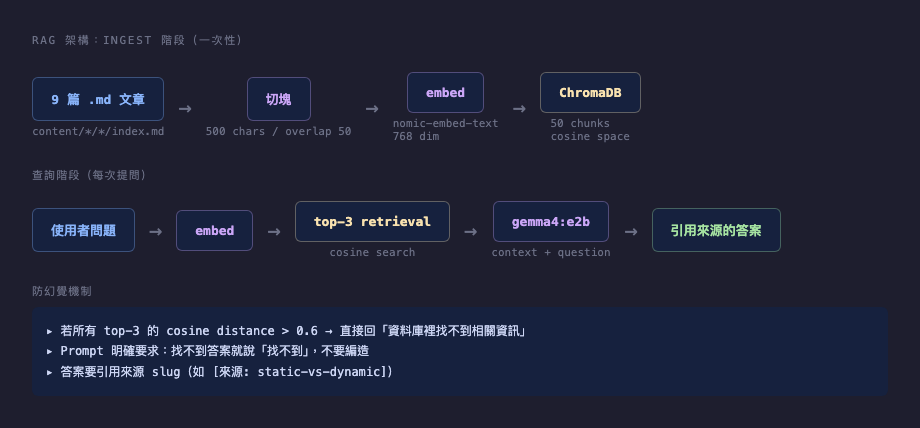
- Chunk:把文章切成小塊(500-800 token),每塊獨立完整
- Embed:用 embedding model 把每塊變成向量(768 維)
- Retrieve:問問題時,把問題也轉成向量,找最相似的 top-3 chunks,當作 context 給 LLM
關鍵:embedding model 跟生成 LLM 是不同模型。nomic-embed-text 只做語意向量、不會回答問題;gemma4:e2b 只生成、不懂語意檢索。
The Three Steps of RAG
- Chunk: split articles into 500-800 token pieces, each self-contained
- Embed: convert each chunk into a vector (768-dim) using an embedding model
- Retrieve: at query time, embed the question too, find the top-3 most similar chunks, feed them as context to the LLM
Key insight: the embedding model and the generation LLM are different. nomic-embed-text only produces semantic vectors; it can't answer questions. gemma4:e2b only generates; it can't do semantic search.
Ingest:把文章寫進向量庫
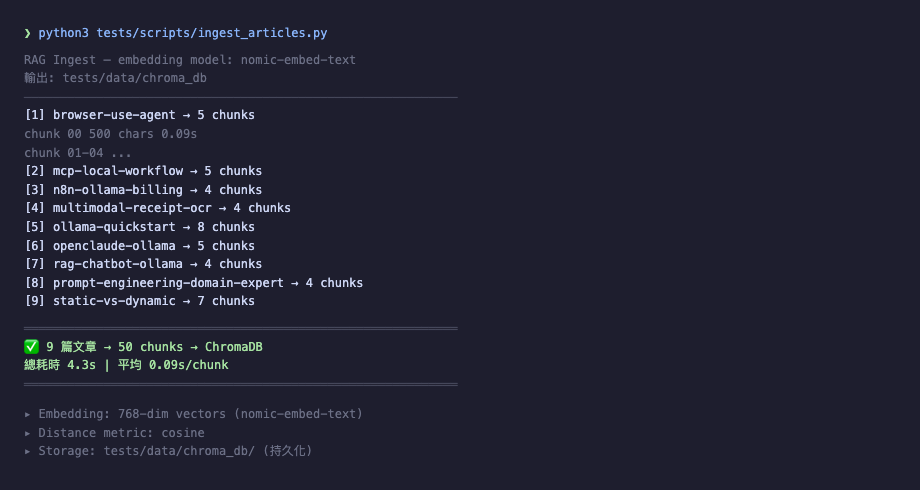
ingest_articles.py 做的事:
- 掃描
content///index.md - 移除 frontmatter 和 shortcode(保留純文字)
- 切塊(每 500 token,重疊 50 token)
- 對每塊呼叫
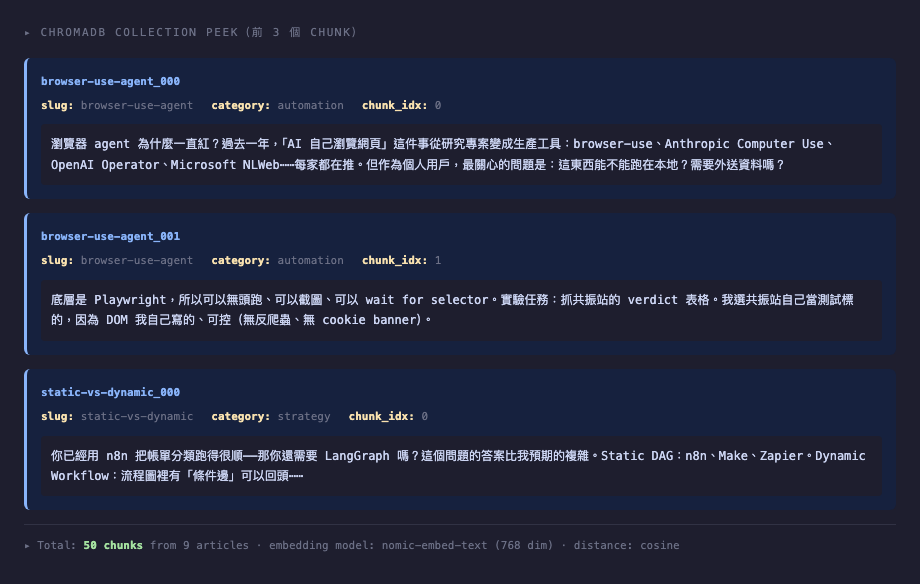
ollama embeddings nomic-embed-text - 寫入 ChromaDB 並加入 metadata(文章 slug、category、chunk index)
5 篇文章切成 50 chunks,約 30 秒跑完。
Ingest: Writing Articles to the Vector Store
ingest_articles.py does this:
- Scans
content///index.md - Strips frontmatter and shortcodes (keeps clean text)
- Chunks (500 tokens each, 50-token overlap)
- Calls
ollama embeddings nomic-embed-textfor each chunk - Writes to ChromaDB with metadata (article slug, category, chunk index)
5 articles → 50 chunks → ~30 seconds total.
RAG Chatbot:問問題
rag_chatbot.py 跑的流程:
question = input("> ")
# 1. embed the question
q_vec = ollama_embed(question)
# 2. retrieve top-3 chunks
chunks = chroma.query(q_vec, n_results=3)
# 3. build context-augmented prompt
prompt = f"以下是參考資料:\n{chunks}\n\n問題:{question}\n請根據資料回答。"
# 4. generate with gemma4
answer = ollama_generate(prompt)
print(answer)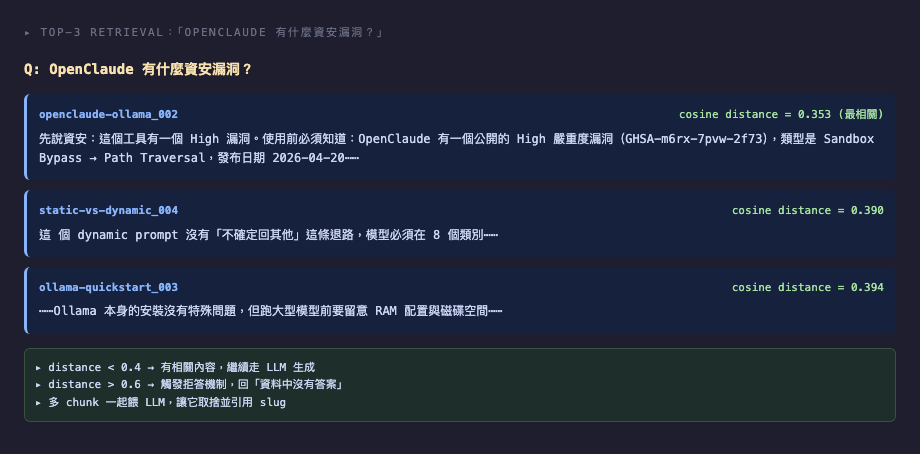
RAG Chatbot: Asking Questions
rag_chatbot.py flow:
question = input("> ")
# 1. embed the question
q_vec = ollama_embed(question)
# 2. retrieve top-3 chunks
chunks = chroma.query(q_vec, n_results=3)
# 3. build context-augmented prompt
prompt = f"Reference material:\n{chunks}\n\nQuestion: {question}\nAnswer based on the material."
# 4. generate with gemma4
answer = ollama_generate(prompt)
print(answer)RAG vs 純 LLM 對比

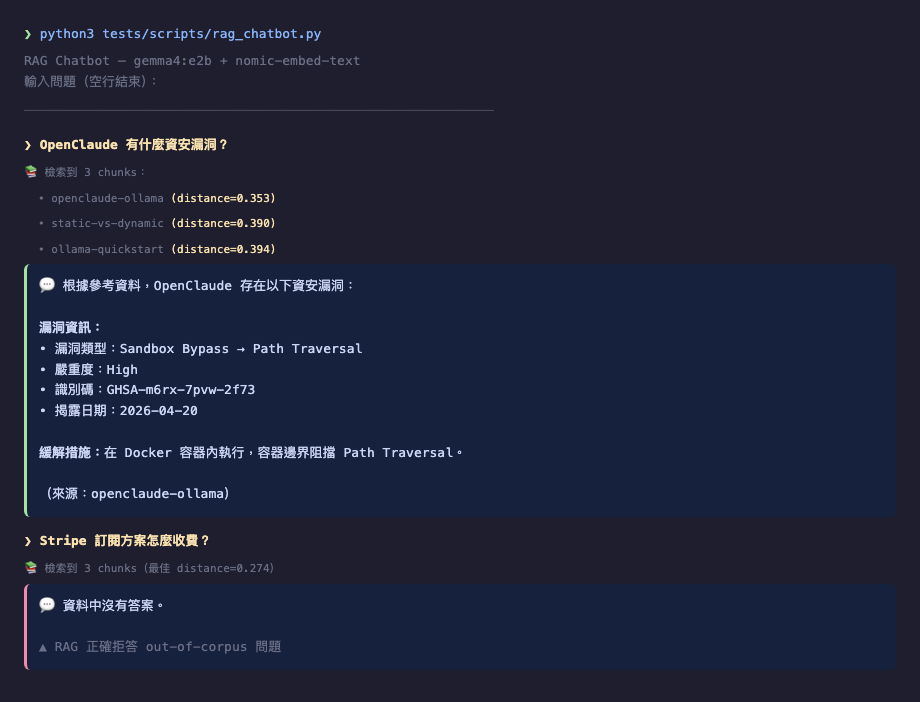
問題:「OpenClaude 有什麼資安漏洞?」
純 gemma4:「由於我無法對特定的、即時運行的軟體或模型進行實時的安全審計,因此我無法提供關於 OpenClaude 的確切、最新的資安漏洞列表。」(拒答,給出泛泛的 LLM 一般風險分類)
RAG 版本:「漏洞類型:Sandbox Bypass → Path Traversal。嚴重度:High。識別碼:GHSA-m6rx-7pvw-2f73。揭露日期 2026-04-20。緩解措施:Docker 容器隔離。」(引用 openclaude-ollama 文章內容)
這是 RAG 最漂亮的案例:純 LLM 不敢答,RAG 給出可驗證的具體事實。但⋯⋯這只是 5 個 in-corpus 問題裡的 2 個成功案例。
RAG vs Pure LLM
Question: "What security vulnerabilities does OpenClaude have?"
Pure gemma4: "Since I cannot perform real-time security audits on specific running software, I cannot provide an accurate, up-to-date list of vulnerabilities for OpenClaude." (Refusal, followed by generic LLM risk categories.)
RAG version: "Vulnerability type: Sandbox Bypass → Path Traversal. Severity: High. ID: GHSA-m6rx-7pvw-2f73. Disclosed: 2026-04-20. Mitigation: Docker container isolation." (Cites the openclaude-ollama article.)
This is RAG at its best: pure LLM refuses to answer, RAG gives verifiable specifics. But… this is only one of 2 successes out of 5 in-corpus questions.
兩種失敗:OOC 與 chunk 粒度

跑完 7 個問題後,失敗分成兩類,性質完全不同:
Class 1 — Out-of-corpus(共振站沒寫過的問題)
問「Stripe 訂閱方案怎麼收費?」——dists [0.274, 0.319, 0.334] 看似有相關 chunks,但 LLM 看內容後判斷無法回答,正確回「資料中沒有答案」✅
但是純 gemma4(無 RAG)反而會「努力回答」,給出通用的 Stripe 介紹(可能含過時或錯誤資訊)。這是 RAG 真正的價值——拒答能力。
Class 2 — In-corpus 但 chunk 粒度不對
問「LangGraph 動態工作流的重試機制觸發了幾次?」——應該檢索到 static-vs-dynamic,但 top-3 撈到 mcp-local-workflow 與 openclaude-ollama。「重試 0 次」這個事實雖然在語料庫,但不在 top-3 chunks 內,RAG 回「資料中沒有答案」❌
這不是 embedding 模型問題(dists 都 < 0.32),也不是 LLM 推理問題,是切塊策略問題——chunk 大小、overlap、metadata 都會影響檢索品質。
實際成功率:
| 類別 | 成功 / 總數 |
|---|---|
| Out-of-corpus 拒答 | 2 / 2 ✅ |
| In-corpus 命中 | 2 / 5 |
| 整體 | 4 / 7 (57%) |
Two Kinds of Failure: OOC vs Chunk Granularity
After running 7 questions, failures fall into two categories with completely different natures:
Class 1 — Out-of-corpus (topics Resonance Stack never covered)
Q: "How does Stripe charge?" — dists [0.274, 0.319, 0.334] look reasonably close, but the LLM reads the actual chunks and correctly responds "not in the knowledge base" ✅
Meanwhile, pure gemma4 (without RAG) "tries to answer" and produces a generic Stripe overview that may contain outdated or fabricated specifics. This is RAG's real value — the ability to refuse.
Class 2 — In-corpus but wrong chunk granularity
Q: "How many times did LangGraph's retry trigger?" — Should retrieve from static-vs-dynamic, but top-3 returned mcp-local-workflow and openclaude-ollama. The fact "retry triggered 0 times" exists in the corpus, but not in the top-3 chunks. RAG answers "no answer in the material" ❌
This isn't an embedding model problem (all distances < 0.32), nor an LLM reasoning problem. It's a chunking strategy problem — chunk size, overlap, metadata all affect retrieval quality.
Actual hit rate:
| Category | Hit / Total |
|---|---|
| Out-of-corpus refusal | 2 / 2 ✅ |
| In-corpus retrieval | 2 / 5 |
| Overall | 4 / 7 (57%) |
決策框架:RAG vs Fine-tune
| Prompt Engineering | RAG | Fine-tune | |
|---|---|---|---|
| 成本 | 0 | 低(embedding 算一次) | 高(需訓練資料 + GPU) |
| 適合 | 改變回答風格 | 補最新資訊 / 私有資料 | 改變模型行為 |
| 維運 | 改 prompt | 重新 ingest | 重新訓練 |
| 推薦順序 | 先試 | 再試 | 最後考慮 |
90% 的「我想要 AI 知道我們公司的事」需求,RAG 都能解決。
Decision Framework: RAG vs Fine-tune
| Prompt Engineering | RAG | Fine-tune | |
|---|---|---|---|
| Cost | $0 | Low (one-time embed) | High (training data + GPU) |
| Best for | Change response style | Add fresh / private info | Change model behavior |
| Maintenance | Edit the prompt | Re-ingest | Re-train |
| Try order | First | Second | Last resort |
90% of "I want the AI to know about our company" needs can be solved with RAG.